| Gathering Data at Scale for Real-World AI From AI as a Service by Peter Elger and Eóin Shanaghy This article discusses gathering data for real-world AI projects and platforms. |
You can save 40% off AI as a Service, as well as of all other Manning books and videos.
Just enter the code psgadget40 at checkout when you buy from manning.com.
Gathering Data from the Web
This article looks in detail at gathering data from websites. Whilst some data may be available in pre-packaged, structured formats, accessible as either flat files or through an API, this isn’t the case with web pages.
Web pages are an unstructured source of information such as product data, news articles and financial data. Finding the right web pages, retrieving them and extracting relevant information is non-trivial. The processes required to do this are known as web crawling and web scraping.
- Web Crawling is the process of fetching web content and navigating to linked pages according to a specific strategy.
- Web Scraping follows the crawling process to extract specific data from content which has been fetched.
Figure 1 shows how the two processes combine to produce meaningful, structured data.
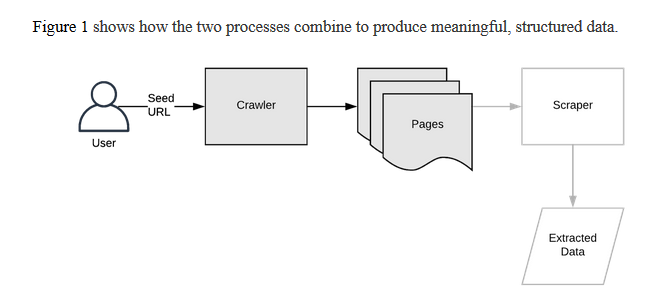
Figure 1. Webpage crawling and scraping process overview. In this article we’re concerned with the crawler part of this picture and the pages it produces as output.
Let’s imagine that we are a conference organizer who wants to scrape some data for their conference web page. Our first step in creating a solution for this scenario is to build a serverless web crawling system.
Introduction to Web Crawling
The crawler for our scenario is a generic crawler. Generic crawlers can crawl any site with an unknown structure. Site-specific crawlers are usually created for large sites with specific selectors for findings links and content. An example of a site-specific crawler could be one written to crawl particular products from amazon.com, or auctions from ebay.com.
Examples of well-known crawlers include:
- Search Engines such as Google, Bing, Yandex or Baidu
- GDELT Project[8], an open database of human society and global events
- OpenCorporates[9], the largest open database of companies in the world
- Internet Archive[10], a digital library of Internet sites and other cultural artifacts in digital form
- CommonCrawl[11], an open repository of web crawl data
One challenge for web crawling is the sheer number of web pages to visit and analyze. When we’re performing the crawling task, we may need arbitrarily large compute resources. Once the crawling process is complete, our compute resource requirement drops. This sort of scalable, burst-prone computing requirement is an ideal fit for on-demand, cloud computing and serverless!
Typical Web Crawler Process
To understand how a web crawler might work, consider how a web browser allows a user to navigate a webpage manually.
- The user enters a webpage URL into a web browser.
- The browser fetches the page’s first HTML file.
- The HTML file is parsed by the browser to find other required site pages such as CSS, JavaScript and images.
- Links are rendered. When the user clicks on a link, the process is repeated for a new
URL.
Listing 1 shows the HTML source for a simple example webpage.
Listing 1. Example Webpage HTML Source
<!DOCTYPE html>
<html>
<body>
<a href=”https://google.com”>Google</a> ①
<a href=”https://example.com/about”>About</a> ②
<a href=”/about”>About</a> ③
<img src=”/logo.png” alt=”company logo”/> ④
<p>I am a text paragraph</p> ⑤
<script src=”/script.js”></script> ⑥
</body>
</html>
- External link
- Absolute internal link
- Relative internal link
- Image resource
- Paragraph text
- JavaScript source
We’ve shown the structure of a basic page. In reality, a single HTML page can contain hundreds of hyperlinks, both internal and external. The set of pages required to be crawled for a given application is known as the crawl space. Let’s talk about the architecture of a typical web crawler and how it’s structured to deal with various sizes of crawl space.
Web Crawler Architecture
A typical web crawler architecture is illustrated in Figure 2. Let’s get an understanding of each component of the architecture and how it relates to our conference website scenario before describing how this might be realized with a serverless approach.
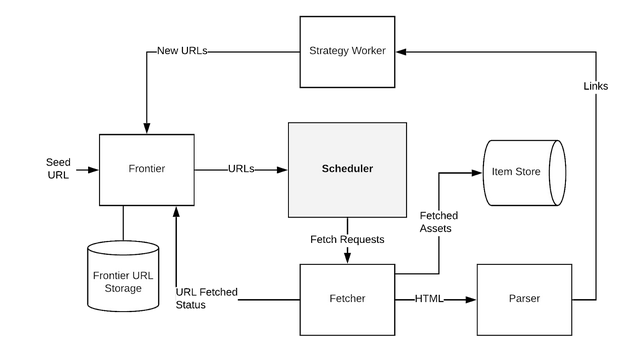
Figure 2. Components of a Web Crawler. The distinct responsibilities for each component can guide us in our software architecture.
- The Frontier maintains a database of URLs to be crawled. This is initially populated with the conference websites. From there, URLs of individual pages on the site are added here.
- The Fetcher takes a URL and retrieves the corresponding document.
- The Parser takes the fetched document, parses it and extracts required information from it. We won’t look for specific speaker details or anything conference specific at this point.
- The Strategy Worker or Generator is one of the most crucial components of a web crawler, because it determines the crawl space. URLs generated by the Strategy Worker are fed back into the Frontier. The Strategy Worker decides:
◦ which links should be followed
◦ the priority of links to be crawled
◦ the crawl depth
◦ when to revisit/re-crawl pages if required
- The Item Store is where the extracted documents or data or stored.
- The Scheduler takes a set of URLs, initially the seed URLs, and schedules the Fetcher to download resources. The scheduler is responsible for ensuring that the crawler behaves politely towards web servers, that no duplicate URLs are fetched, and that URLs are normalized.
Is Crawling Amenable to Serverless Architecture?
If you’re wondering whether Serverless Architecture is a valid choice for the implementation of a web crawler, you have a good point! Web Crawlers, operating at scale, require fast, efficient storage, caching and plenty of compute power for multiple, resource-intensive page rendering processes. Serverless applications, on the other hand, are typically characterized by short-term, event-driven computation and the absence of fast, local disk storage.
Is the system in this article worthy of production use or are we embarking on a wild experiment to see how far we can push our cloud-native ideology?! Using a more traditional “farm” of servers has advantages, such as Amazon Elastic Compute Cloud (EC2) instances. If your crawling needs require a constantly running workload at large volumes, you might be better off choosing a traditional approach.
We must remember the hidden cost of maintaining and running this infrastructure, the operating system and any underlying frameworks. Also, our crawling scenario is for on-demand extraction of data regarding specific conference websites. This “burst” behavior is suitable to an elastic, utility computing paradigm. A serverless implementation may not be optimal from a caching perspective but, for our scenario, this doesn’t have a major impact. We’re more than happy with this approach given that we pay $0 when the system isn’t running and we don’t have to worry about operating system patches, maintenance or container orchestration and service discovery.
For our web crawler, we’re dealing with conferences. Because these constitute a minority of all web pages, there’s no need to crawl the entire web for such sites. Instead, we’ll provide the crawler with a “seed” URL.
On the conference sites, we’ll crawl local hyperlinks. We won’t follow hyperlinks to external domains. Our goal is to find the pages which contain the required data such as speaker information and dates. We aren’t interested in crawling the entire conference site, and for this reason we’ll also use a depth limit to stop crawling after reaching a given depth in the link graph. The crawl depth is the number of links which have been followed from the seed URL. A depth limit stops the process from going beyond a specified depth.
Basic Crawlers vs. Rendering Crawlers
Basic crawlers fetch only HTML pages and don’t evaluate JavaScript. This leads to a much simpler and faster crawl process, but this may result in us excluding valuable data.
It’s now common to have web pages that are rendered dynamically in the browser by JavaScript. Single Page Applications (SPAs) using frameworks like React or Vue.js are examples of this. Some sites use server-side rendering with these frameworks and others perform pre-rendering to return fully-rendered HTML to search engine crawlers as a search engine optimization (SEO) technique. We can’t rely on these being universally employed. For these reasons, we opt to employ full rendering of web pages, including JavaScript evaluation.
A number of options are available for rendering web pages when there’s no user or screen available.
- Splash[12], a browser designed for web scraping applications
- Headless Chrome[13] with the Puppeteer API[14]. This runs the popular Chrome browser and allows us to control it programmatically.
- Headless Firefox[15] with Selenium[16]. This option is a Firefox-based alternative to Puppeteer.
For our solution, we’re going to use headless Chrome. We chose this option as there are readily-available Serverless Framework plugins for use with AWS Lambda.
| Legal and Compliance Considerations for Web Crawling The legal status of web crawling can be a contentious are. On one hand, the site owner makes content publicly available. On the other hand, heavy-handed crawling can have an adverse impact on the site’s availability and server load. Needless to say, the following doesn’t represent legal advice. Here are a few best practices that are regarded as polite behavior.
+https://aiasaservicebook.com).
In particular, we need to make sure that we limit the concurrency per domain/ IP or that we choose a reasonable delay between requests. These requirements are a consideration in our serverless crawler architecture. At the time of writing, the AWS Acceptable Use Policy prevents “Monitoring or crawling of a System that impairs or disrupts the System being monitored or crawled.” [18] Note also that some websites implement mechanisms to prevent web scraping. This can be done by detecting IP address or User Agent. Solutions like CloudFlare [19], or Google reCaptcha [20] use more elaborate approaches. |
Serverless Web Crawler Architecture
Let’s take a look at how we map our system to a canonical architecture. Figure 3 provides us with a breakdown of the system’s layers and how services collaborate to deliver the solution.
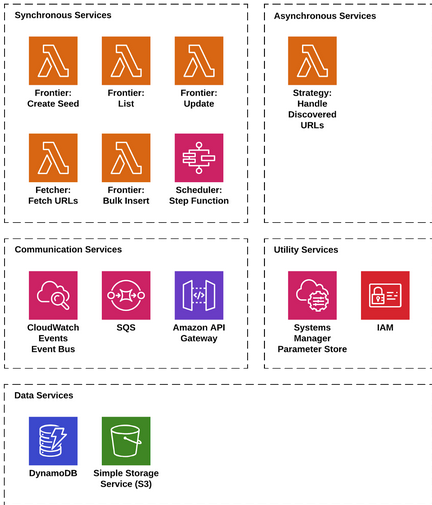
Figure 3. Serverless Web Crawler System Architecture. The system is composed of custom services implemented using AWS Lambda and AWS Step Functions. SQS and the CloudWatch Events service are used for asynchronous communication. Internal API Gateways are used for synchronous communication. S3 and DynamoDB are used for data storage.
The system architecture shows the layers of the system across all services. Note that, in this system, we have no front-end web application.
- Synchronous tasks in the Frontier and fetch services are implemented using AWS Lambda. For the first time, we introduce AWS Step Functions to implement the Scheduler. It’s responsible for orchestrating the Fetcher based on data in the Frontier.
- The Strategy service is asynchronous and reacts to events on the event bus indicating that new URLs have been discovered.
- Synchronous communication between internal services in our system is handled with API Gateway. We have chosen CloudWatch Events and SQS for asynchronous communication.
- Shared parameters are published to Systems Manager Parameter Store. IAM is used to manage privileges between services.
- DynamoDB is used for Frontier URL storage. An S3 bucket is used as our Item Store.
| Build or Buy? Evaluating Third Party Managed Services Writing an article that espouses the virtues of managed services has a certain irony, because it emphasizes the importance of focusing on your core business logic. Our crawler is quite simple and also domain-specific. This is some justification for writing our own implementation. We know from experience that simple systems grow in complexity over time. Therefore, implementing your own anything should be your last resort. Here are two rules of thumb for modern application development:
Such services can be found outside the realm of your chosen cloud provider. Even if Amazon Web Services has no off-the-shelf web crawling and scraping services, look beyond AWS and evaluate the third-party offerings. This is a worthwhile exercise for any service you’re thinking of building. For example, if you want to implement a search feature in your application, you might evaluate a fully-managed Elasticsearch service such as Elastic[23] or a managed search and discovery API like Algolia[24]. If you’re interested in evaluating third-party web scraping services, take a look at the following.
|
That’s all for now.
If you want to learn more about the book, check it out on our browser-based liveBook reader here.